

为啥蜘蛛只爬js不爬文章页啊
 发布时间:2025-06-03 02:28
发布时间:2025-06-03 02:28 发布者:好资源AI
发布者:好资源AI 浏览次数:
浏览次数:蜘蛛爬虫的工作原理一直是大家讨论的焦点,尤其是对于站长们来说,如何让蜘蛛快速抓取自己的网站内容,是一个大问题。很多人可能会觉得,哦,爬虫不就是要抓取网页吗?这很简单,但实际上并非如此。有很多细节是普通人不了解的,呃,今天我们就来聊聊一个常见的问题-为啥蜘蛛只爬JS,不爬文章页啊?有时候,网页的文章内容明明已经准备好,可蜘蛛却就是不“欣赏”这些内容,真的挺让人头疼的。
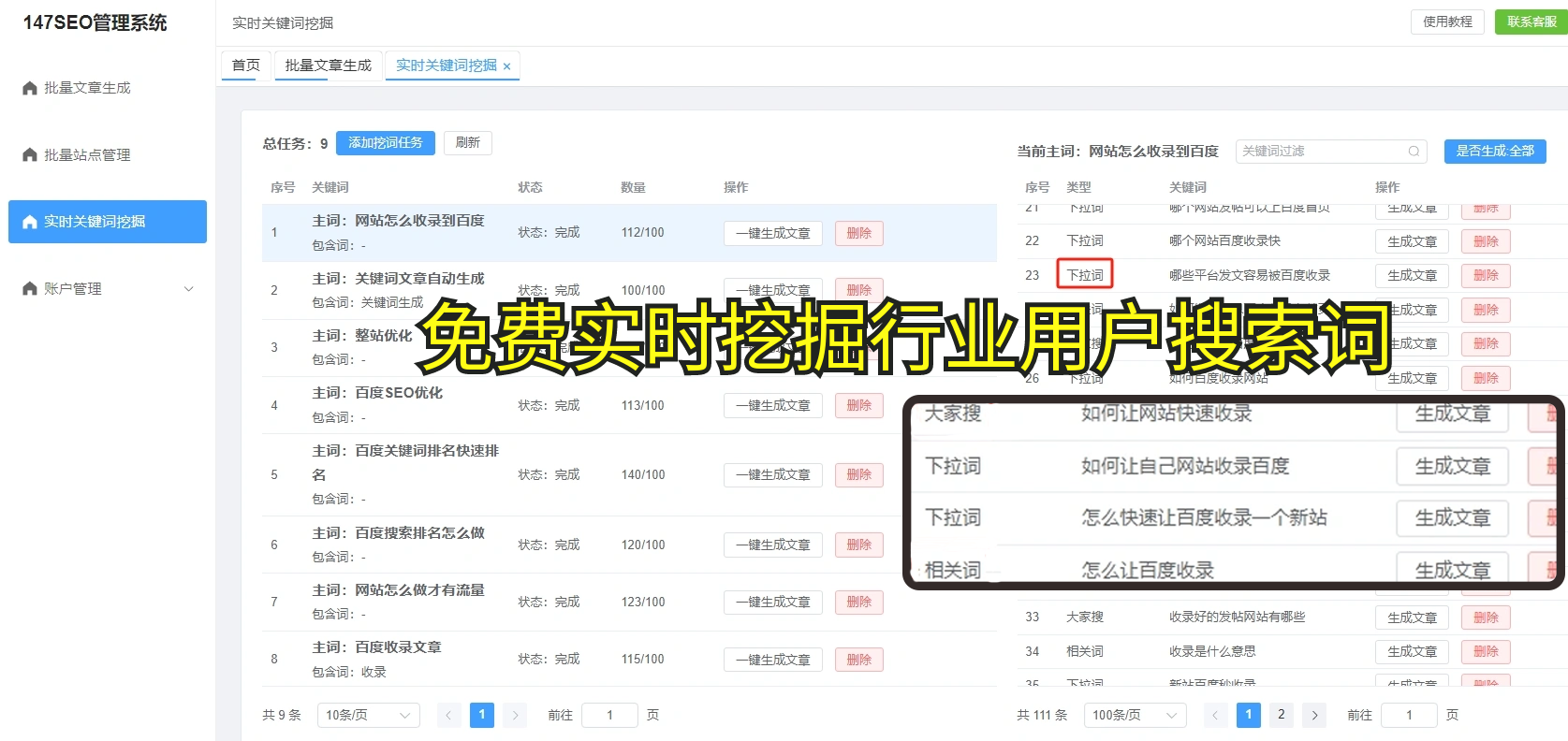
首先呢,我个人觉得,蜘蛛的爬取逻辑其实是比较复杂的。蜘蛛它们“爬”网页的时候,先是通过网页的源代码来获取页面信息,如果网页是纯HTML格式的,那蜘蛛基本上能顺利地爬取到。可是如果网页是通过JavaScript生成的,嗯,这就得看你网站的爬虫配置了。有一些蜘蛛,比如说Googlebot,它能理解JavaScript生成的内容,所以能够抓取到这些动态内容。但问题来了,很多时候咱们站长并没有正确配置爬虫的抓取规则,这就导致爬虫可能忽略了你页面上那些用JS加载的内容。
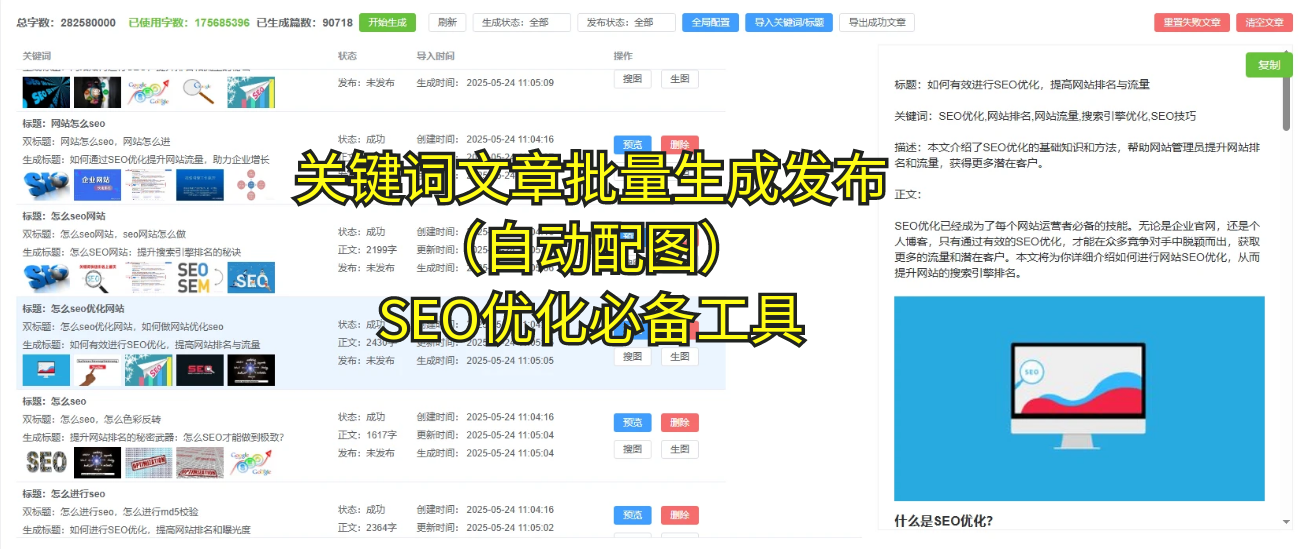
说到这里,呃,很多朋友可能就会问,难道我得把所有内容都写成HTML才能让蜘蛛抓取吗?其实不完全是这样,咱们可以通过一些技术手段来“告诉”爬虫,呃,如何更好地抓取页面内容。比如说,使用服务器端渲染(SSR)或者静态渲染,这样JS加载的内容就会在页面加载时直接呈现给爬虫,蜘蛛也能“看见”你想让它抓取的东西了。

现在说回到为什么有些爬虫只爬JS内容呢?其实,这也和爬虫的工作方式有关系。不同的搜索引擎会根据自己的算法和爬虫策略进行优化。Google的蜘蛛是能够解析JavaScript的,但其他一些小的爬虫就不一定有这个能力了。所以,如果你的网站依赖大量JavaScript来加载内容,可能就会导致一部分不支持JS的爬虫爬取不到你的网站内容。
另外啊(稍微打个岔),其实也有很多优化工具可以帮助你更好地分析爬虫抓取情况。比如说“宇宙SEO”,它就能为站长提供精准的爬虫抓取报告,帮助你发现哪些页面被爬取,哪些没有被抓取,甚至还能为你推荐改进的策略。所以,如果你正在面临爬虫抓取不到文章页的问题,可以尝试借助这些工具,看看问题出在哪里。
如何确保自己的页面能够被更好地爬取呢?有几个小技巧,确保网站的robots.txt文件没有阻止蜘蛛抓取文章页。要在页面中嵌入一些结构化数据,例如使用Schema.org标记,这样不仅有利于爬虫抓取,还能在搜索结果中显示更丰富的摘要信息。
问:我的网站使用了JavaScript,为什么Google爬虫还是无法抓取文章内容?
答:可能是因为JavaScript加载的内容没有正确地呈现,建议你使用服务器端渲染(SSR)或者预渲染技术,确保内容在页面加载时已经可见,从而让爬虫能够顺利抓取。
问:如何检测我的网站是否被蜘蛛成功抓取?
答:可以通过Google Search Console来查看爬虫抓取报告,检查哪些页面被抓取,哪些没有抓取,了解抓取情况并进行优化。
通过这些措施,站长们可以最大限度地提升自己网站内容的爬取率,避免因为技术原因错失SEO优化的机会。当然啦,呃,如果你的网站内容更新频繁,最好定期检查一下爬虫的抓取情况,确保自己的网站能够在搜索引擎中获得良好的曝光。







